在數據流處理中,有界數據 (Bounded Data) 和無界數據 (Unbounded Data) 是兩個重要的概念,這裡的界是時間邊界,指數據流的時間終點,我們可以把它像像成一個「閘門」的感覺,在處理有界數據時,我們會將閘門放下,這時新數據都會被擋在閘門外無法流入;反之,無界數據沒有閘門,因此新資料仍會不斷流入。總結來說:
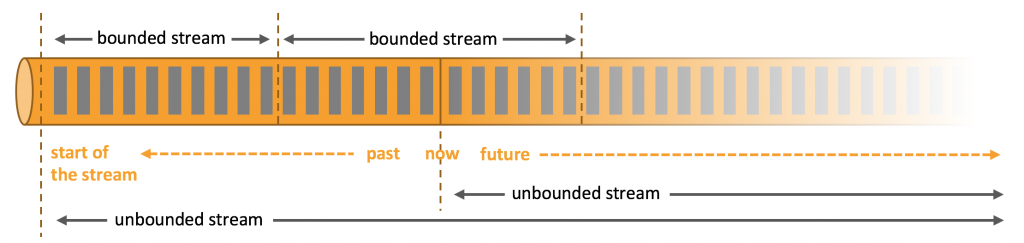
前面提到有界數據是靜止不動的,因此我們在處理時會先蒐集完數據再進行計算,以批 (batch) 為單位處理資料,一般來說速度較慢,通常是使用在離線的數據處理上,這種情況下雖然不需要考慮新資料的流入,但也更加關注數據規模。
常見的批處理計算有:MapReduce、Spark
Spark Streaming 屬於微批處理,本質上還是批處理,差別在於將每個 batch 切得更小,以此來加快每批數據的處理速度,進而達到近似流處理的效率。
流處理須兼顧無界數據「連續」且「持續變動」兩個特點,數據的蒐集與計算是同時發生的,通常是使用在及時的數據處理上,如交易系統、串流分析與日誌分析等,關注的重點在於低延遲。
常見的流處理計算有:Flink、S4、Storm、Samza
Apache Kafka 本身不屬於流處理計算,而是一個分散式的訊息佇列,用於可靠地接收、存儲和分發數據消息,因此常與流處理計算引擎搭配使用。
大部分的大數據資料處理都屬於批處理與流處理的範疇,但有少部分情況下,使用特定的計算方法可以加速處理的效率,如:
由於批處理與流處理所的使用情境與使用技術差異甚大,過去企業採用的架構多是直接採用兩套不同技術,然而這樣的作法其實存在著一些缺點,因此又有人提出了流批一體的架構,下一篇文章就將為大家介紹大數據處理的兩個經典架構:Lambda 與 Kappa。
大数据的计算模式:批量计算和流式计算
批处理计算与流处理计算的区别是什么?
Process Unbounded and Bounded Data


 iThome鐵人賽
iThome鐵人賽